Issue 9: Accuracy, Precision and the Obscured Target
Why Measurement Quality Matters

In This Issue:
📖 Book Update: A Forecast, Revised
🎤 Upcoming Talks
📝 The Obscured Target: Why Measurement Quality Matters
❓ Reader Question
📖 Book Update: A Forecast, Revised
The official Amazon release date for From Heatmaps to Histograms is April 29, though we’d been pushing hard to get it out by early-March in time for RSA. I had a book signing planned at the RSA bookstore and a few other events lined up around the conference.
I got word late last week that mid-March isn’t going to happen. I’ll be honest, I went through all five stages of grief on this one. Denial was particularly convincing for about 48 hours.
The good news is that we’re only talking a few weeks, not months. Early April is the current target, which means RSA attendees will just have to settle for my sparkling personality instead of a signed copy.
Those of you who have been reading since Issue 8 may remember that I said I was “90% confident” the book would land between March 4 and 13. This is a good teaching moment. A 90% forecast means I believed there was roughly a one-in-ten chance the real date would fall outside that range, and that’s what happened. The Bayesian mindset doesn’t treat that as a defeat. New information came in, I updated my belief, and the estimate moved accordingly. That's forecasting working the way it should. If you never land outside your forecast ranges, your ranges are probably too wide, and you’re not being honest about your uncertainty.
In other news, I redesigned the website at heatmapstohistograms.com and added full chapter descriptions, so if you want to know what’s inside the book, check out the “Inside the Book” section. I also sent the manuscript to a number of people across the industry and received some incredibly generous feedback. Here are three of my favorites:
From Heatmaps to Histograms is a significant contribution to our profession, and would be required reading for anyone in my organization if I was still a CISO. Brilliantly written for those with little or no background in quantitative risk measurement, it also will be very useful to those with years of experience. This is just further evidence that Tony is one of the leading contributors to the future of our profession.
-Jack Jones, Creator of FAIR
I’ve been measuring various aspects of cyber risk for over 20 years. In the early days, I saw the lack of reliable data as the primary roadblock to the broad adoption of quantitative approaches to managing risk. I’m still a strong proponent of better data, but I now view practicality as the chief impediment. A recurring “Yeah, but how?” dominates conversations on cyber risk quantification, but practical answers and examples remain scarce. That’s why I’m so excited about this book. Tony strikes the perfect balance of what you need to know and what you need to do to make CRQ work for you.”
-Wade Baker, Ph.D., Partner, Cyentia Institute and Professor, Virginia Tech
Tony Martin-Vegue makes a strong case for replacing certain popular risk assessment methods and he goes further with practical approaches needed to implement better methods. He adds multiple case examples and step-by-step procedures with the primary goal of making even more quantitative concepts accessible to every reader. I highly recommend his book.
-Douglas Hubbard, author and measurement expert
I’m thrilled that they liked the book, and I’m grateful for the time they spent reading it.
🔗 Pre-order on Amazon | 🔗 Book website
🎤 Upcoming Talks
I have a few events planned:
March 24, 2026 “The Future of Cyber Risk Intelligence” FAIR Institute Seminar at RSAC 2026, San Francisco
I’m closing out the FAIR Institute’s seminar at RSA with a session on what boards and regulators will expect next from cyber risk programs. The talk covers the shift from backward-looking risk reporting to forward-looking risk intelligence, where AI fits (and doesn’t), and the skills that will define the next generation of risk analysts. The FAIR seminar at RSA is always one of the best events of the week, and I’d encourage anyone attending the conference to make time for it.
April 21, 2026 “Did We Solve the Data Problem? Judgment, Beliefs, and Risk in the AI Age” SIRAcon 2026 — Keynote
I’m honored to be keynoting SIRAcon this year. My talk argues that we never had a data problem in risk quantification; we had a judgment problem wearing a data costume. Now that AI has made data abundant and cheap, the real bottleneck is fully exposed: judgment under uncertainty. The session develops three ideas: risk estimates are beliefs rather than truths, uncertainty is not a data gap AI can close, and data must earn the right to influence belief before it shapes decisions.
SIRAcon is my favorite conference because it is model-neutral, vendor-neutral, and entirely dedicated to advancing risk practices. I’d encourage anyone serious about the craft to attend.
📝 The Obscured Target
Why Measurement Quality Matters
A few months ago, I asked an LLM to help me research breach frequency data for a risk assessment I was running. It gave a very convincing response: a specific industry, a specific incident type, a time range, and a precise frequency. I was almost persuaded by the exact number, the clean citations, and a reference to what appeared to be a Ponemon report I hadn’t seen before. The output had that satisfying feeling of precision.
Nonetheless, I did what I always tell people to do. I checked the sources.
The Ponemon report didn’t exist. It wasn’t a miscited year or a different title. The report was completely fabricated (a hallucination). In human parlance, we would call that a lie.
Here’s the disturbing thing: I am very well-versed in industry reports, especially data breach frequency. My spidey sense tingled, though I think for many other subjects I would have a hard time distinguishing a good output from a hallucination. My brain was ready to accept it and move on. If I’d been any less disciplined, those fake numbers would have gone straight into my model.
That experience sent me back to something I’d been teaching for years without fully appreciating its implications. AI introduces a new dimension into how we think about the accuracy and precision of our measurements.
Accuracy and Precision: The Four Targets
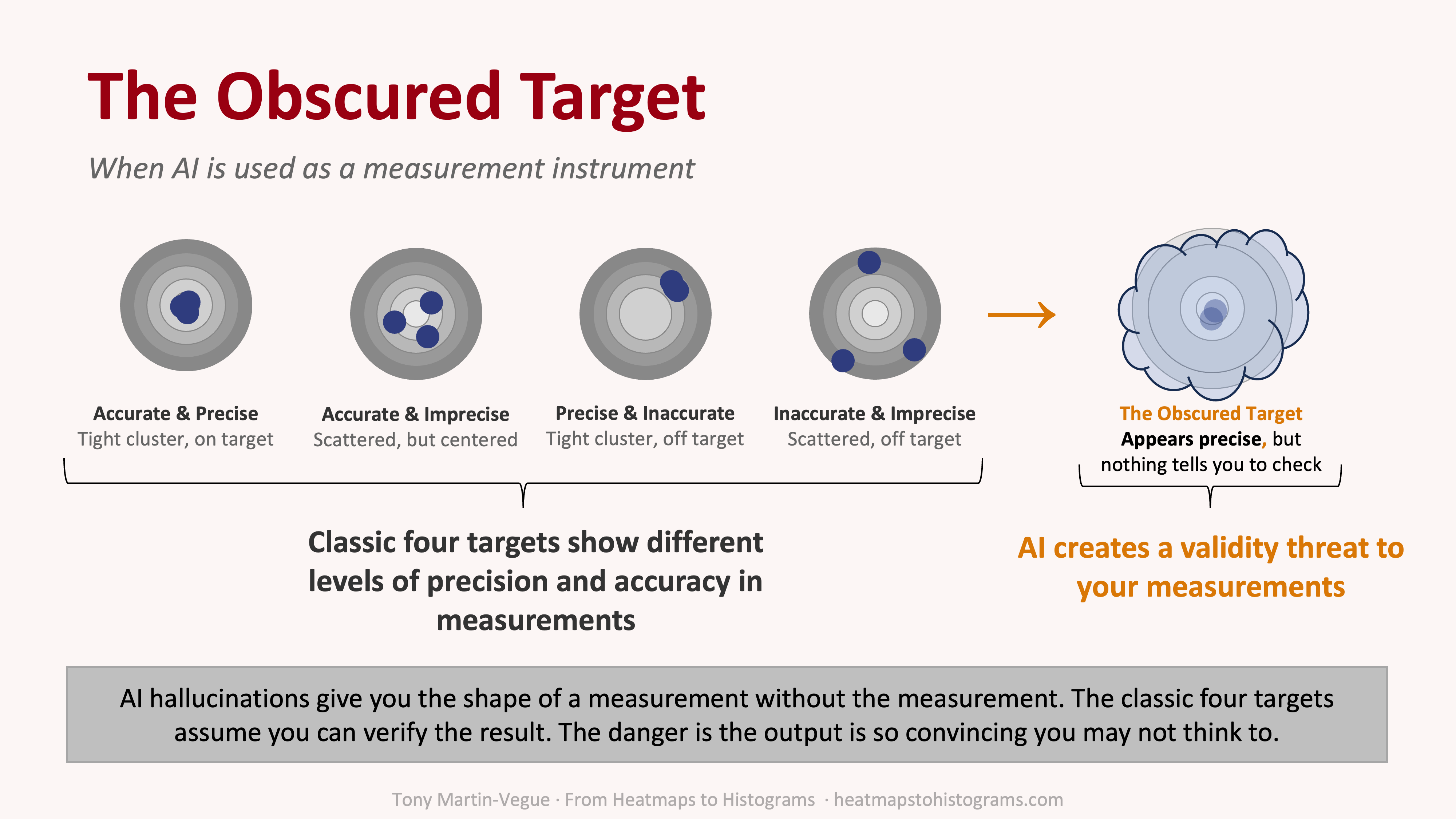
If you’ve spent any time studying metrology, the science of measurement, or any field that draws from it, like decision science, risk quantification, and many others, you’ve probably seen the four targets.
It’s a teaching aid used to illustrate a foundational concept in measurement: accuracy and precision. The typical image shows four bullseyes, four shot patterns with each one illustrating a different combination of accuracy and precision. It’s one of those visuals that’s been around forever because it works so well, and you see it once and you get it.
As I mentioned earlier, this concept comes from metrology. Metrology is about how we know what we know when we measure things. How do you know your scale is correct? How do you know your thermometer isn’t drifting? How do you know the number you’re looking at reflects reality?
These questions matter every time you make a decision based on a measurement. In cyber risk quantification, we’re making decisions based on continuous measurements, such as loss estimates, frequency ranges, and confidence intervals. It all depends on whether our measurement process is working. Keep in mind that risk quantification, including FAIR, is a forecast, and a forecast is a type of measurement.
I teach the concepts of accuracy and precision using the four-targets analogy whenever I teach FAIR. It’s one of the first concepts I cover because it reframes how people think about estimates. Most people walk in thinking the goal is to get the “right” number, and the four targets help them see that measurement quality is more nuanced than that.
Let me walk through them quickly, because you need all four to understand the fifth.
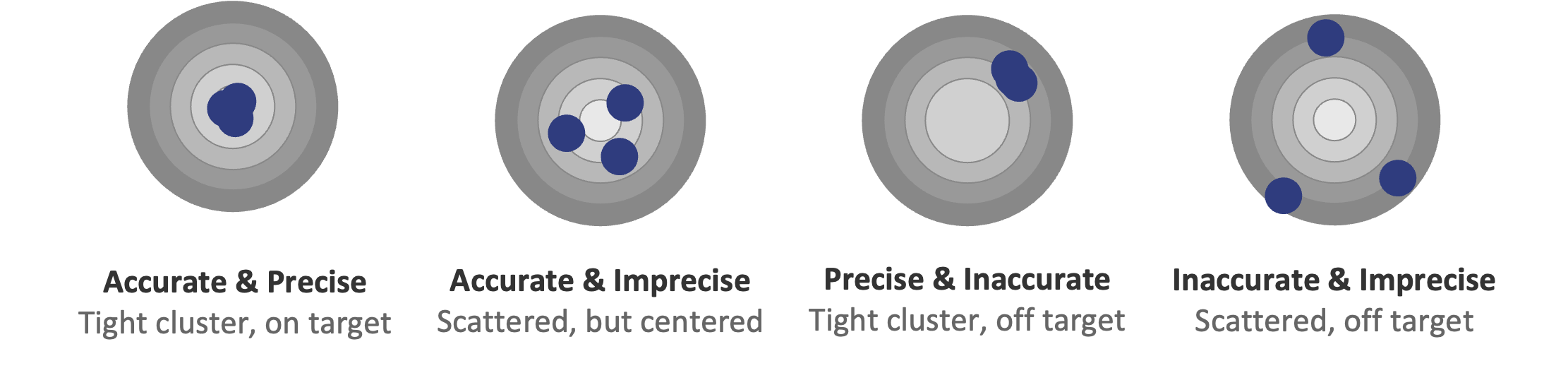
Accurate and Precise. Tight grouping, dead center. This is the ideal. Your estimates cluster close together and they’re centered on the true value. In CRQ terms, your model is well-calibrated and your inputs are solid. If and when the results of forecasts are known, the forecasts land consistently where they should.
This can be expensive, though. Getting here requires good data, experienced analysts, validated models, and time. If you’re chasing this standard for every assessment, you’ll burn through resources fast. It’s like insisting on a gourmet meal when a solid sandwich would get you through the day just fine. Save the five-star treatment for the risks that justify the investment.
Accurate and Imprecise. Scattered shots, centered on the target. Your estimates vary widely, though on average you’re in the right zone.
This is the sweet spot for early-stage analysis. You’re not nailing down exact numbers, you’re just figuring out if this risk matters. Does it change your decision if the loss is $2 million or $8 million when you’re comparing it to something that might cost $200 million? Probably not. Wide yet accurate ranges can drive good decisions, so don’t let the pursuit of precision slow you down when direction is what you need.
Precise and Inaccurate. Tight grouping, off to the side. This is bias. Your estimates are consistent, consistently wrong. Maybe you’re anchoring on a vendor report, your SME has a blind spot, or your measurements have a structural flaw.
This one is dangerous because it feels like you’re doing well. The numbers look clean and cluster nicely, but you’re missing the target entirely, and I’ve seen this one in the wild many times: a team producing beautifully consistent assessments quarter after quarter, all anchored in the same flawed assumption no one questions. The precision gives you false confidence, and you might never go looking for the problem.
Inaccurate and Imprecise. Scattered shots, nowhere near the center. You’re all over the place and not even close. Your measurement process is broken.
The irony is that this is also expensive. You’re spending time and effort producing numbers that mean nothing. You might as well not measure at all, or rather it’s worse than not measuring, because at least then you know you’re guessing. Here, you think you’re doing analysis.
The Obscured Target

These four states cover most of what can go wrong with a measurement process. Bias, variance, systematic error, random noise: it all maps somewhere on this framework.
All four targets share one assumption, though: you can see where the shots landed.
You shoot. You walk up to the target. You look. The holes are there. Maybe they’re clustered, maybe they’re scattered, though you can verify the result against reality. You have access to ground truth.
With AI as your measurement instrument, that assumption breaks down.
When you ask an LLM to estimate breach frequency, pull loss data from a report, or synthesize threat intelligence, it gives you an answer, often a confident-sounding answer with citations. Unless you are disciplined enough to verify, you have no idea if those shots hit anything real.
This isn’t a precision problem. It’s not a bias problem. It’s something else entirely.
I call it the obscured target.
Picture a tight grouping, dead center. It’s textbook accurate and precise, except the target is hidden behind fog. You can’t see where the shots landed. You’re trusting the instrument’s report of where it hit.
Here’s an example: imagine stepping on a scale that always reads 165 pounds. Every time you weigh yourself, you get a consistent number. It looks accurate, it looks precise. There’s a problem you don’t know about, though: the display is disconnected from the sensor. It’s just showing you a stored value. The number has the shape of a measurement and feels like a measurement, yet nothing is being weighed in reality. Day to day, as your weight fluctuates, the instrument is wrong. It doesn’t have a measurement problem you can fix, like bias you can correct or imprecision you can average out. It has something worse: no measurement is happening at all. That’s what happened to me with those fake Ponemon numbers. The output wasn’t inaccurate in the normal sense. It was invented.
The “Obscured Target” Is a Validity Threat
The four targets describe properties of a measurement system: accuracy, precision, and bias. These properties are diagnostic, meant to help you evaluate whether your instrument is working. Metrologists would tell us the correct response to AI hallucination is the same response you’d give to any suspect instrument: calibrate it. Check the output against known values. Validate. If it’s wrong, fix it or stop using it.
They would be right.
If you can’t verify the output directly, decompose the estimate into components you can verify. Don’t treat the LLM as an oracle. Treat it as one input and calibrate it against known reference data, the same way you’d calibrate any instrument. This is a calibration and decomposition problem, and measurement science has solved such problems for a long time.
The framework works; the question is whether practitioners know to apply it when the output looks this good.
The obscured target isn’t a new measurement quality quadrant. It’s a category error to put it on the same level as accuracy and precision. What it is, in measurement theory terms, is a validity threat: a condition that undermines your ability to evaluate the instrument at all.
Think of it this way. The four targets all assume you can walk up to the bullseye and look. That’s the prerequisite. If you can see where the shots landed, you can diagnose accuracy, precision, bias, whatever. The obscured target breaks that prerequisite. It’s not telling you something new about the instrument’s performance. It’s telling you that you can’t evaluate the instrument’s performance in the first place.
When someone hands you a biased estimate, you can detect it and correct it. When someone hands you an imprecise estimate, you can invest in better data. The danger comes when the output looks so complete that you don’t think to verify it. You can always pull back the curtain, check the source, find the original data, validate the citation. The problem isn’t that verification is impossible. It’s that nothing about the output signals that verification is necessary.
Before you ask whether your AI-assisted estimate is accurate or precise, ask the more basic question: can I see the target? That question comes first.
What This Means for CRQ
We’re increasingly using AI to support risk analysis: estimating frequencies, interpreting incident data, extracting figures from documents, summarizing threat reports, just to name a few. I’ve written extensively about how AI can accelerate risk work and I use it every day.
The problem isn’t that AI is inaccurate. Sometimes it is, sometimes it isn’t. The harder question is whether we can tell which situation we're in.
The risk isn’t uniform across all AI-assisted tasks, either. Asking an LLM to extract a number from a report you provide is relatively low risk, since the source document is right there and you can check. Asking it to generate a breach frequency estimate from its training data is where the obscured target lives. The AI is producing a number with no source document behind it. Know which situation you’re in before you decide how much verification the output needs.
The classic four targets assume observability. We can validate results and compare what the instrument reported to what happened. AI breaks that feedback loop by giving you high apparent precision with no built-in signal that verification is needed.
In my book, From Heatmaps to Histograms: A Practical Guide to Cyber Risk Quantification, I have an easy-to-remember rule on how to think about AI: Jack Sparrow from Pirates of the Caribbean. AI, like Jack Sparrow, is charming, fast, and brilliant at what it does, though it’s optimized for completing the adventure (or the conversation). Neither will tell you when it’s making things up. At least Jack Sparrow knows when he’s lying. Current AI systems will hand you fabricated data with the same confidence as verified facts, and there’s no flashing warning light. The supervision has to come from you.
Before you evaluate whether your AI-assisted estimate is accurate or precise, ask a more basic question: can I see the target?
If the answer is no, you’re not measuring. You’re trusting.
We’re relying on AI more and more to assist with, and in many cases perform, our measurements. That’s a massive improvement in CRQ and a real time saver. As we hand more of the measurement process to AI, though, we take on a new responsibility, which is making sure what comes back is real.
❓ Reader Question
I’ve started using AI to help with risk assessments and my team loves it because it’s fast, but my manager is skeptical and says we can’t trust the outputs. How do I find the middle ground?
Your manager isn’t wrong, and you’re not wrong either. The answer depends on which part of the workflow you’re handing to AI.
I think about this as a question of where the information is coming from. When the AI is working with something you provided, like summarizing a report you uploaded or generating Monte Carlo code from parameters you specified, the risk is low because you can check the output against your own inputs. The source material is sitting right there. If the AI gets something wrong, you’ll probably catch it.
The risk changes when the AI is generating information from its training data. Estimating breach frequencies, citing industry studies, producing loss figures: these are the tasks where the obscured target lives. You have no way to verify the output without going and finding the original source yourself, which is the step that feels redundant when the AI’s answer looks so polished. That feeling is the danger.
The middle ground your manager is looking for is a workflow where verification scales with risk. Use AI freely for the tasks where your inputs are the source of truth. When the AI is the source, treat the output the way you’d treat a claim from a colleague you’ve never worked with before: interesting, possibly useful, not yet trusted. Verify before it goes into your model.
If you can explain that distinction to your manager, you’ll probably find more common ground than you expect.
✉️ Contact
Have a question about this, or anything else? Here’s how to reach me:
Reply to this newsletter if reading via email
Comment below
Connect with me on LinkedIn
🌐 Elsewhere
I share shorter thoughts on risk, metrics, and decision-making on LinkedIn.
Book updates, chapter summaries, tools, and downloads are at www.heatmapstohistograms.com
My longer-form essays and older writing live at www.tonym-v.com
❤️ How You Can Help
✅ Tell me what topics you want covered: beginner, advanced, tools, AI use, anything ✅ Forward this to a colleague who’s curious about CRQ
✅ Click the ❤️ or comment if you found this useful
If someone forwarded this to you, please subscribe to get future issues.
Thanks for reading.
—Tony
I ordered the book last month, and I am eager to dive into it. Cheers.