What the CIA Figured Out About the Word "Probably" in 1964
Everyone on your team reads "probably" and "highly likely" as different numbers, and how you can prove it in twenty minutes

Most of the risk teams I work with, whether they’ve reported to me or I’ve been brought in to consult, are new to risk measurement. Before I get into any of the heavier material like probability distributions and Monte Carlo methods, I run a little game. Well, it’s more of a parlor trick, because I already know how it ends. It takes about twenty minutes, and I’m convinced it changes more minds about the need for real risk measurement than any deck I’ve ever put together. The idea comes from Doug Hubbard’s book The Failure of Risk Management, where he goes deep on this exact problem.
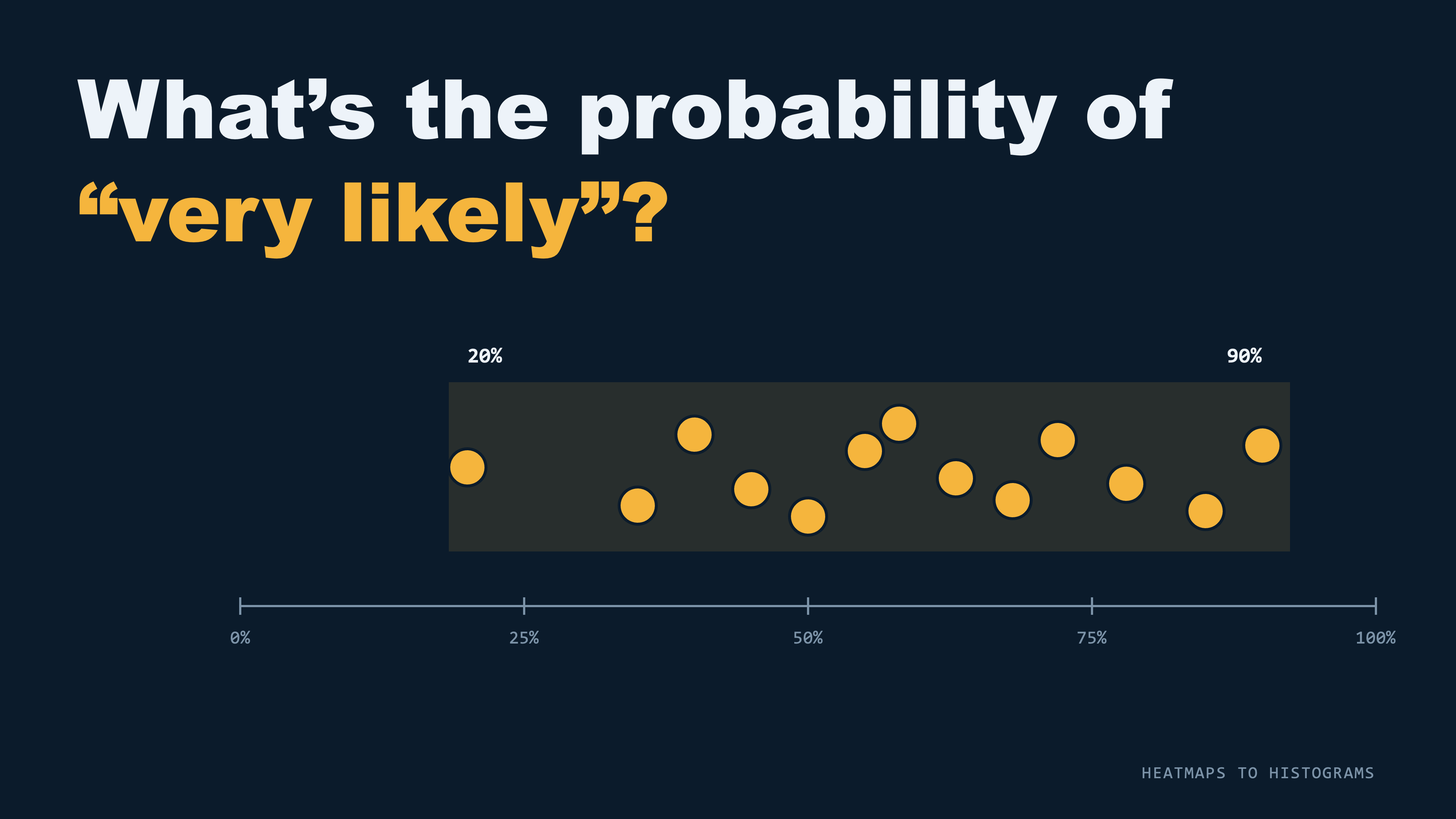
Here’s how it works, and you don’t need anything fancy for it. I’ve run it in a Google Form, and I’ve also run it with a stack of index cards. You take ten or so of the words we all use to describe risk: “high,” “low,” “likely,” “unlikely,” “very likely,” “almost certain,” and so on. Then you ask everyone in the room to assign a probability to each one on their own, no conferring. Ask, what probability does “very likely” mean to you, personally? Give them about five minutes.
Then you pull up everyone’s answers next to each other.
This is the part I love. One person’s “very likely” is 90 percent. The person sitting right next to them put down 40. I’ve had it come in as low as 20, which is a pretty generous use of the word “very.” These aren’t strangers pulled off the street, either. It’s the risk team! They sit in the same meetings, read the same reports, and every one of them walked in sure that everybody else meant about the same thing they did. They didn’t, and you can watch it land on their faces.
Here’s the “aha” moment of the workshop, and I spell it out for them right there. Suppose your latest risk report calls a threat “highly likely.” One person reads that and assumes it’s basically going to happen this year. Someone else reads the same words and files it under “maybe once every ten years.” They both nod. They both go off and build budgets, mitigation plans, spending decisions, sometimes entire strategic roadmaps, all on top of completely different understandings of the same threat. Even worse, they leave the meeting certain they reached consensus, when the truth is anything but.
When I first started running that game, I figured it’s a cool party trick. It’s not. This turns out to be one of the oldest problems in the whole business of making predictions, and the people who took it most seriously weren’t in security or risk at all.
The CIA Noticed This in 1964
Back in 1964, a CIA analyst named Sherman Kent got fed up with this exact problem and wrote a paper about it, now declassified, called “Words of Estimative Probability.” Kent ran the CIA’s Board of National Estimates, and he kept watching analysts brief senior officials with phrases like “it is almost certainly a military airfield” or “it is possible they will turn this into a strategic staging base.” Nobody reading those briefings had a reliable way to know what “almost certainly” meant in plain numbers. The reader was left to guess, the same way your CFO guesses when your report says “high.”

Kent went through example after example of language that sounded precise and communicated nothing. Take “serious possibility.” One analyst writes it meaning 30 percent. The officer reading it hears 70. That is not a rounding error. In intelligence work, that is the gap between getting ready for an invasion and missing the signals entirely.
So Kent proposed something simple but effective. He built a table that mapped the words to numbers and got people to agree on it. “Almost certain” would mean about 93 percent, give or take six. “Probable” would mean roughly 75, give or take twelve. If we insist on using words to talk about probability, the least we can do is agree on what the words mean.

The intelligence world adopted versions of his idea over the next few decades, but the core problem still never went away. People keep hearing the same words differently. The only real change is that most organizations outside of intelligence have never even tried to fix it.
The NATO Study Made It Worse (In a Good Way)

If Kent made the case in theory, a 1977 study made it impossible to ignore. A researcher named Scott Barclay and his colleagues, working on a handbook for the Department of Defense, sat 23 NATO military officers down and handed them a set of nearly identical sentences about whether the Soviets would invade Czechoslovakia. The only thing that changed from one sentence to the next was the probability word.
The sentences read like this:
“It is highly likely that the Soviets will invade Czechoslovakia.”
“It is almost certain that the Soviets will invade Czechoslovakia.”
“We believe that the Soviets will invade Czechoslovakia.”
“We doubt that the Soviets will invade Czechoslovakia.”
Sixteen versions in all, one probability word each, and every officer was asked to put a percentage on each.
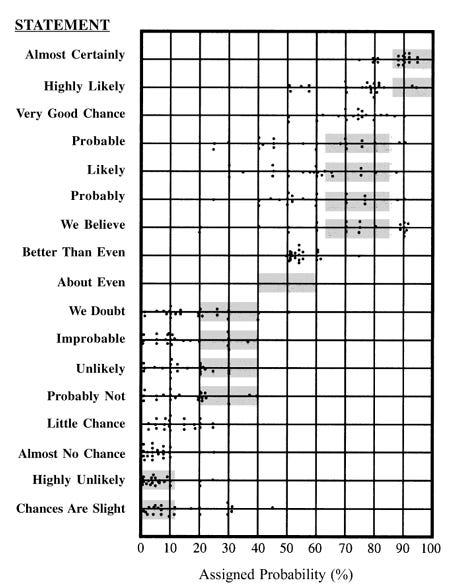
The answers were all over the place. “We doubt” overlapped with “probably.” “We believe” ran from about 50 percent to nearly 90. Words that were supposed to mean clearly different things turned out to be more or less interchangeable, depending on who was reading them. Keep in mind these were trained military officers, sizing up the exact kind of question they sized up for a living, and they still couldn’t agree on what the words meant.
That study has been repeated in different forms for almost fifty years, and the result never changes. Give any group a list of probability words, ask them to put numbers on them, and you get the same wide, overlapping mess. It isn’t a quirk of one group or one culture; it is just how language behaves when you point it at uncertainty.
This Is Happening in Your Risk Program Right Now
Here’s why I’m telling you about Cold War spies in a cyber risk newsletter. If your organization runs a risk register, a heat map, or any report built on words like “high,” “medium,” “low,” “likely,” or “unlikely,” you have inherited Sherman Kent’s 1964 problem wholesale. The labels are different, and the stakes are corporate instead of military, but the failure is the same.
This is the whole reason I push so hard on quantification. Numbers don’t need translating.
The same thing happens every time you publish a risk register. It flags a threat as “high likelihood,” and everyone who reads that line fills in a number of their own without noticing they’re doing it. Your CISO might be thinking 70 percent. The CFO reads the exact same line and lands closer to 40. The board member who caught a breach in the headlines that morning is probably up around 90. They are all reading the same entry, and they have each walked away with a different idea of how much trouble you’re in.
This is the whole reason I push so hard on quantification. Numbers don’t need translating. When the report says “a 20 percent chance that losses top $5 million,” the analyst who wrote it and the executive reading it are finally holding the same thing. There’s no gap between what one meant and what the other heard.
A qualitative risk matrix skips that step completely. It runs on the same fuzzy words the CIA spent decades trying to pin down. A 5x5 grid with “very likely” in one box and “possible” in another is doing the exact trick Kent warned about in 1964: it manufactures the feeling of agreement without any of the substance.
Don’t Take My Word for It
I reference Kent’s paper and the NATO study all the time, but reading about a problem is not the same as feeling it. So I built a small tool that lets you feel it on your own.
It’s called “Can You Beat a CIA Officer?” You get seven of the usual probability words (remote, unlikely, possible, even chance, likely, very likely, almost certain) and a slider for each one. You set your own numbers, lock them in, and it shows you how your answers stack up against four real intelligence standards: Kent’s 1964 CIA scale, the NATO AJP-2.1 standard, the US Intelligence Community Directive 203, and the UK PHIA Probability Yardstick.
There’s no winning score, because there’s no correct answer. The point is to see the gap between what you think “likely” means and what these standards say it means, which is a decent stand-in for the gap between you and whoever is sitting across the table in your next meeting.
Try it yourself, then send it to your team or your boss. Once a group that makes decisions together watches their own numbers land in completely different spots, the argument for putting real numbers on risk gets a lot shorter.
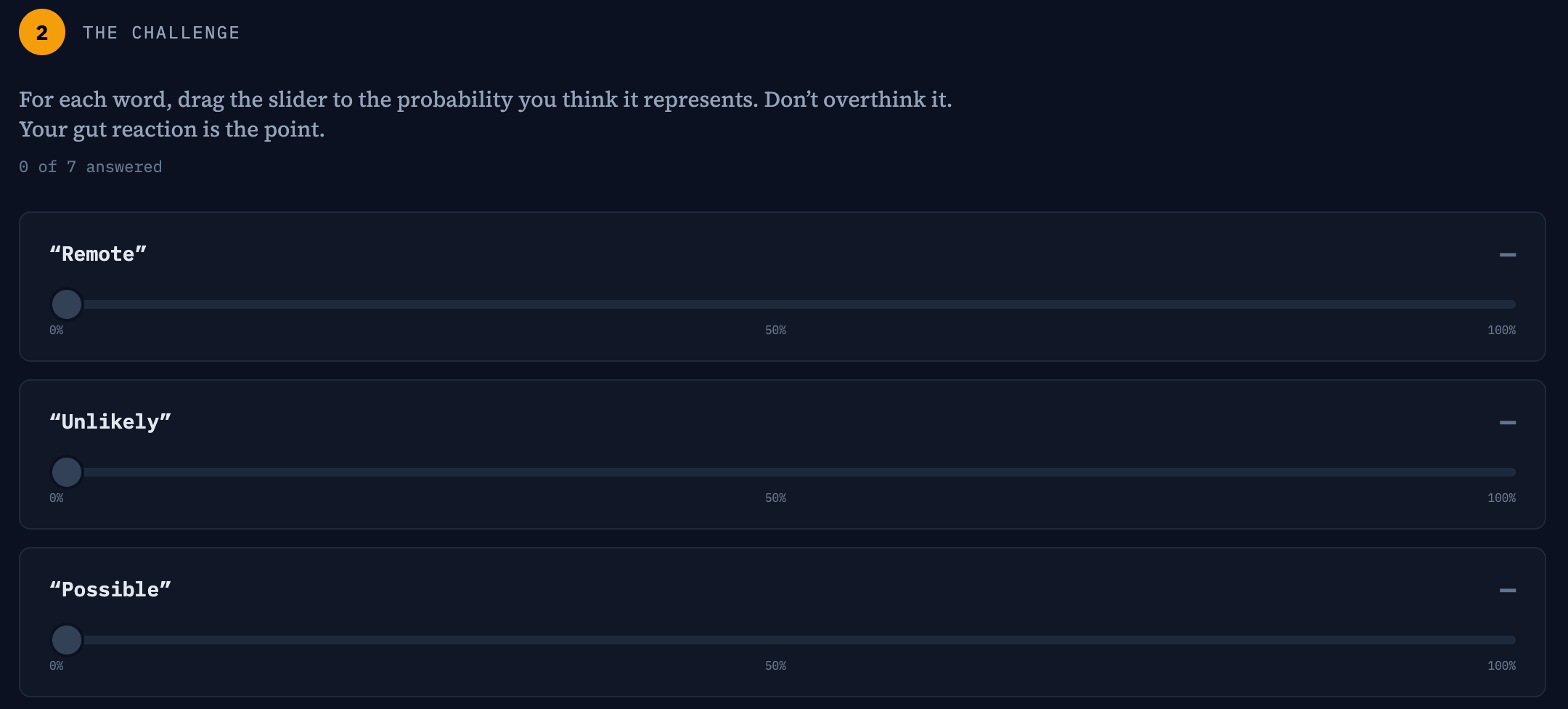
🔗 Try the Probability Word Challenge → https://tonym-v.github.io/heatmapstohistograms/words-of-estimative-probability.html
The Fix Isn’t New Either
John Locke said this back in the 1600s: “So difficult it is to show the various meanings and imperfections of words when we have nothing else but words to do it with.” Three hundred years later, we’re still laboring over words and what they mean. We use vague language to talk about an uncertain future, we assume everyone hears it the same way, and we make real decisions on top of that assumption.
The fix has been sitting right there the whole time, and it isn’t complicated: use numbers, ranges, and probabilities instead of adjectives. The spies worked this out decades ago. The rest of us are still catching up.
👉 Before You Go
If this cleared something up, do me a favor and forward it to the one person on your team who still reports risk in reds, yellows, and greens. Better yet, run the twenty-minute game with your own team this week. I’ll be curious how wide your spread comes out. Short on a team to test? Take the challenge solo.
📘 The book. From Heatmaps to Histograms is out now, and it hit #1 in Amazon’s Computer Network Security category. You can buy it anywhere books are sold. The ebook is available now from Springer and Barnes & Noble, and the publisher is working on a Kindle edition. 🔗 Amazon · 🔗 Book site
🎤 Where I’ll be. I’m running a workshop at DEF CON’s Noob Village this year: ninety minutes of quantitative risk for absolute beginners, no background required. More details coming soon.
✉️ Contact
Have a question about this, or anything else? Here’s how to reach me:
Reply to this newsletter if reading via email
Comment below
Connect with me on LinkedIn
🌐 Elsewhere
I share shorter thoughts on risk, metrics, and decision-making on LinkedIn.
Book updates, chapter summaries, tools, and downloads are at www.heatmapstohistograms.com
My longer-form essays and older writing live at www.tonym-v.com
Thanks for reading,
Tony